AMD’s Radeon Open Compute platform (ROCm) is an open source development platform for HPC/Hyperscale-class computing. ROCm is AMD’s effort to get their market share in the DL, AI, Crypto Mining/HPC realm that is dominated by Nvidia. This has been the case because Nvidia had a monopoly over the GPU market at the time and had large cash reserves, which meant that they could afford to invest early in CUDA and get developers onboard.
Keeping Nvidia’s monopoly in mind, AMD’s ROCm aims to get developers using CUDA to eventually switch to their ecosystem so that they can write code that will run on both AMD and Nvidia GPUs (ROCm and CUDA respectively). Using the ROCm ecosystem, developers can write code that runs on both AMD and Nvidia GPUs (using Heterogeneous-Computing Interface for Portability, HIP). It also allows you to convert existing code written for CUDA to ROCm code (via HIPify).
ROCm is essentially a collection of software that includes everything from runtimes to libraries and developer tools. I will be focusing on components and packages that a developer might be exposed to while writing code using ROCm or a CUDA developer might use to get their code converted from CUDA to ROCm.
HIP
HIP stands for Heterogeneous-Computing Interface for Portability. It’s a C++ dialect which helps convert CUDA code to portable C++ Code. HIP has almost no negative impact over coding using traditional CUDA and allows developers to code in a single-source C++ programming language with various features like templates and C++11 Lambdas. HIP should be used when CUDA Applications need to be converted to portable C++ code, or when new projects are being made that should work for both AMD and Nvidia GPUs. HIP is syntactically similar to CUDA and most CUDA API calls can be converted in place: cuda -> hip. HIP supports a strong subset of CUDA runtime functionality.
Developers can use several languages alongside ROCm:
-
ROCm/HIP
-
OpenCL - Use when you have an existing project written in OpenCL and portability between various OSes (Windows, Linux, Mac OS) and hardware platforms (also supports x86 CPUs and various FPGAs and DSPs) is needed.
-
Anaconda Python using Numba
Programming with HIP:
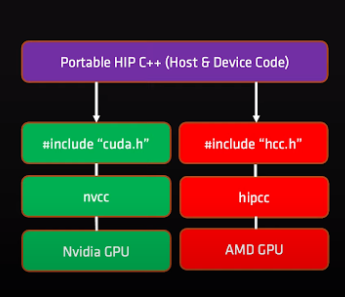
How HIP can compile code for Nvidia and AMD GPUs
(hipcc is now replaced with hip-clang)
Each application has what is called host code and device code. The host is the CPU and is the location where host code runs. The device on the other hand is the GPU and is where the device code is run.
| Host | Device |
|---|---|
| The host is the CPU | The device is the GPU |
| Host code runs here | Device code runs here |
| Entry point is the ‘main’ function | Device codes are launched via “kernels” |
| The HIP API can be used to create device buffers, move between host and device, and launch device code. | Instructions from the host are enqueued into streams. |
| C++ like syntax and features | C-like syntax |
-
Device Kernels:
-
In HIP, kernels are executed on a “grid”. This grid is what you map your problem to.
-
AMD GPUs can support 1D, 2D and 3D grids but most problems map well to 1D grids.
-
Each dimension of the grid is divided into equal sized “blocks”, and every block consists of multiple “threads”.
-
The threads are the things that do the actual work, the grids and blocks are just organizational constructs.
-

Example of a 1D grid
HCC/HIP-Clang:
HCC was AMD’s compiler driver (based on recent versions of CLANG/LLVM) which compiles the C++ code into HSAIL/GCN device code for AMD GPUs. However, HCC was recently replaced by HIP-Clang with the release of v3.5.0 of ROCm.
HIPify
A big point of stress for AMD is to try and make code conversion an easy task. Code written in CUDA can easily be converted to HIP code using HIPify. There are two ways to accomplish this:
- hipify-perl
-
hipify-perl is a perl based script which basically uses regex to perform string based conversion of CUDA code to HIP code.
-
Because it simply performs string based operations to perform conversion, it is easy to use, doesn’t check the CUDA code for correctness and doesn’t have dependencies on 3rd party tools.
-
However, the above points are also part of its downsides. Along with this, several constructs such as macro expansion cannot be transformed by hipify-perl.
- hipify-clang
-
hipify-clang on the other hand is a more convoluted method which also results in better conversion. It is a clang based tool that converts CUDA source into an abstract syntax tree, which is being traversed by transformation matchers. After applying all the matchers, the output HIP source is produced.
-
Since it’s an actual translator, it is able to handle any constructs (that will be parsed correctly, otherwise it’ll report an error accordingly).
-
One thing to note is that it will not be able to transform CUDA code which is incorrect, and it also has a dependency that CUDA should be installed
While ROCm does support the use of OpenCL, HIP has a lot of advantages over it which should be taken into consideration while making a choice. Some of these advantages are:
-
Developers can code in C++ as well as mix host and device C++ code in their source files. HIP C++ code can use templates, lambdas, classes and so on.
-
The HIP API is less verbose than OpenCL and is familiar to CUDA developers.
-
Because both CUDA and HIP are C++ languages, porting from CUDA to HIP is significantly easier than porting from CUDA to OpenCL.
-
HIP uses the best available development tools on each platform: on Nvidia GPUs, HIP code compiles using NVCC and can employ the nSight profiler and debugger (unlike OpenCL on Nvidia GPUs).
-
HIP provides pointers and host-side pointer arithmetic.
-
HIP provides device-level control over memory allocation and placement.
-
HIP offers an offline compilation model.
When ROCm was initially released, AMD worked on OpenCL and HIP ports of CAFFE to show how little work goes into making an HIP port vs an OpenCL port.
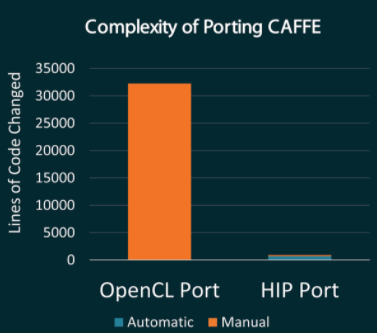
Amount of work required to port to OpenCL vs HIP
HIP provides the following APIs and features:
-
Devices (hipSetDevice(), hipGetDeviceProperties())
-
Memory management (hipMalloc(), hipMemcpy(), hipFree())
-
Streams (hipStreamCreate(),hipStreamSynchronize(), hipStreamWaitEvent())
-
Events (hipEventRecord(), hipEventElapsedTime())
-
Kernel launching (hipLaunchKernel is a standard C/C++ function that replaces «< »>)
-
HIP Module API to control when and how code is loaded.
-
CUDA-style kernel coordinate functions (threadIdx, blockIdx, blockDim, gridDim)
-
Cross-lane instructions including shfl, ballot, any, all - Most device-side math built-ins.
-
Error reporting (hipGetLastError(), hipGetErrorString())
ROCm has various libraries that it supports. Most of them are direct equivalent to existing CUDA libraries, however there are still a few libraries that CUDA has that ROCm does not support. A few of the available libraries are:
-
rocBLAS - Basic Linear Algebra Subprograms implemented on top of ROCm. (CUDA uses cuBLAS instead)
-
hipBLAS - hipBLAS is a BLAS marshalling library which allows developers to either use rocBLAS or cuBLAS as backends.
-
rocRAND - rocRAND provides functions to generate pseudo-random and quasi-random numbers. While it is implemented in HIP and optimised for AMD GPUs, it was also run on CUDA based GPUs. (Equivalent library in CUDA - cuRAND)
-
rocFFT - rocFFT is used to compute Fast Fourier Transforms (FFTs) and is written in HIP. It can also run on both AMD GPUs and compiled with the CUDA compiler for Nvidia GPU devices. (Equivalent library in CUDA - cuFFT)
-
rocSPARSE - rocSPARSE includes basic linear algebra subroutines for sparse matrices and vectors. (Equivalent library in CUDA - cuSPARSE)
OpenCL
Since I described ROCm earlier, it also makes sense to give an overview about OpenCL, SYCL and SPIR-V due to their role in heterogeneous computing.
OpenCL is a framework for writing programs that execute across various platforms from GPUs, CPUs, FPGAs to DSPs. It is maintained by the Khronos group and specifies languages based on C99 and C++11 for programming these devices. It also provides APIs to control the platform and execute programs on the compute devices. OpenCL provides a standard interface for parallel computing using task and data-based parallelism.
SYCL - SYCL is a cross-platform abstraction layer that builds on OpenCL that enables code for heterogeneous processors to be written in a single source code using C++. SYCL allows for single source development where C++ template functions can contain both host and device code that use OpenCL acceleration. SYCL hides a lot of the complexities of OpenCL and allows developers to use various OpenCL features via different parts of the SYCL API.
SPIR-V - SPIR-V enables high-level language front-ends to emit programs in a standardized intermediate form to be ingested by Vulkan, OpenGL or OpenCL drivers. Since various GPUs have significantly different machine code, it makes sense for the backend compiler to be in the device drivers. However, there is no need to include frontend compilers in the device drivers. SPIR-V eliminates the need to include front-end compilers in device drivers and allows a wide range of languages and framework frontends to run on various different hardware architectures.
From the OpenGC document, the immediate goals of OpenGC are to:
-
Clean up existing documentation of AMD’s stack and write clear tutorials
-
Compile ROCm stack based PyTorch build and make it work on AMD GPU
-
Make PyTorch built with ROCm - now OpenGC - stack work on Nvidia GPUs!
For point 2, AMD has a write-up for building PyTorch for ROCm here: https://rocmdocs.amd.com/en/latest/Deep_learning/Deep-learning.html?highlight=pytorch#building-pytorch-for-rocm
I haven’t been able to compile ROCm stack based PyTorch myself since I do not have access to a modern AMD GPU (or Nvidia for that matter). However if I did, a potential next step would have been to compile a ROCm stack based PyTorch build and compare performance between that on an AMD GPU vs CUDA based PyTorch on an equivalent Nvidia GPU. After that, the next step would have been making ROCm based PyTorch run on an Nvidia GPU and compare performance between ROCm based PyTorch and CUDA based PyTorch.
References: